Troubleshooting Guide
1. Logs
Git MultiSite logs Git and replication events in several places:
- Admin UI: Growl messages
- The growl messages provide immediate feedback in response to a user's interactions with the Admin UI. Growls are triggered only by local events and will only display on the node (and in the individual browser session) in which the event was triggered.

Growl messages appear in the top right-hand corner of the screen and will persist for a brief period (15 seconds in most cases) or until the screen is refreshed or changed.Always check the dashboard
If you are troubleshooting a problem we strongly recommend that you check the Dashboard's Replicator Tasks panel as well as the log files. While we added the gowl messaging as way giving administrators an immediate alert for events as they happen, they are not intended to be used as the main method of tracking failures or important system events. - multisite.log
- Basic events that relate to the starting up/shutting down of Git MultiSite.
e.g.2014-01-15 16:45:17: [3442] Starting ui 2014-01-15 16:53:24: [3571] Starting replicator - replicator.yyymmdd-hhmmss.log
- Events relating to the start up and shutdown of the replicator, and also logging. This log never includes information about the actual operation of the replicator, for that you need to see the log files located in the replicator's own logs directory (see below)
- watchdog.log
- Logs the running of the watchdog process which monitors and maintains the running of the Git MultiSite processes.
- The log file name is
gitms.log. - The maximum size of a log file is set at 100MB.
- The maximum number of logs is limited to 10.
- The VCSRollingFileAppender offers some benefits over Log4j's default RollingFileAppender. It has a modified rollover behavior so that the log file
gitms.logis saved out with a permanent file name (rather than being rotated). Whengitms.logreaches its maximum size it is saved away with the namegitms.log.<Date>. - When the maximum number of log files is reached, the oldest log file is deleted.
- ERROR
- (previously "Severe") Message level indicating a serious failure.
- WARN
- A message level indicating a potential problem.
- INFO
- Interesting runtime events (startup/shutdown). Expect these to be immediately visible on a console, so be conservative and keep to a minimum.
- CONFIG
- Details of configuration messages.
- DEBUG
- Provides a standard level of trace information.
- TRACE
- Provides a more detailed level of trace information.
- ALL
- (previously "Finest") Provides a boggling level of trace information for troubleshooting hard to identify problems.
- Log in to a node, and click the REPOSITORIES tab.

Go to the repository
- Click one of the listed repositories.
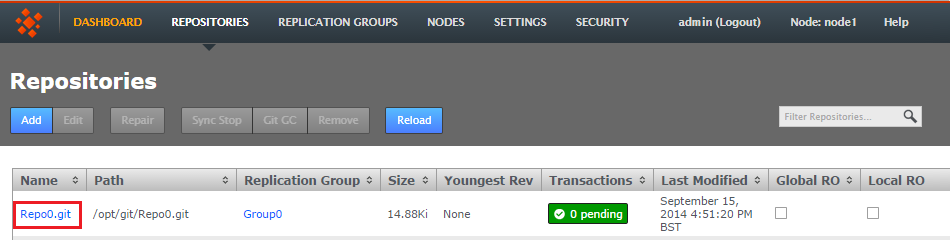
Click a repository
- Click the Consistency check.
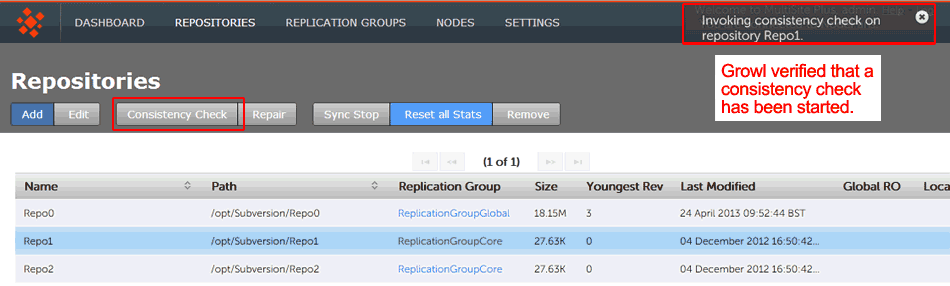
Consistency check in action
You see a growl message "Invoking consistency check on repository <Repository Name>".Known issue: Don't run a consistency check if the repository has been removed from one of the nodes.
There's currently a problem with running a consistency check on a repository if the replica on one or more or more nodes has been deleted. In this situation a "Highest Common Revision" task will appear on the dashboard and will remain permanently in a 'pending' state. Until we resolve this problem you shouldn't run the consistency checker on a repository if it has been removed from the file system of any of your nodes. - Click on the DASHBOARD tab. The results of the consistency check will appear on the Replicator Tasks widget - you'll need to select All Tasks, instead of the default Pending Tasks.
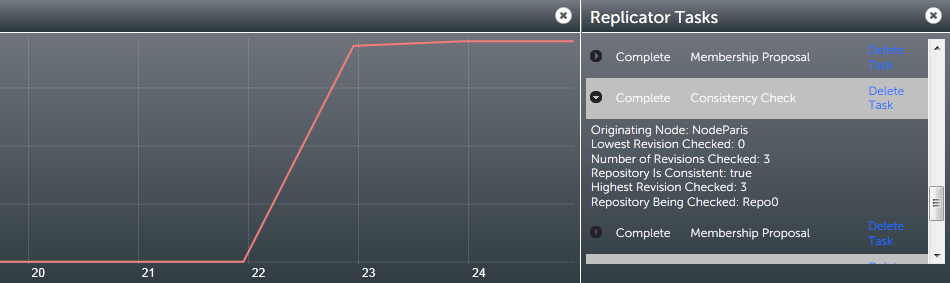
Repository replicas need to be identical - are they?
- Originating Node:
- The node from which the check was requested.
- Lowest Revision Checked:
- The oldest revision compared across all nodes.
- Number of Revisions Checked
- Total number of revisions checked.
- Repository is Consistent
- The result of the check as a 'true' or 'false' statement.
- Highest revision Checked
- The youngest revision compared across all nodes.
- Repository Being Checked
- The name of the repository that has had its consistency checked.
- Log into the admin console, click Settings.

Settings
- Go to the end of the list of editable settings, you'll see a Scheduled Consistency Check Enabled? checkbox. Tick the box to enable the schedule. The time between checks (if enabled) is set in the Scheduled Consistency CHeck Frequency (Hours) box.

Enable and set the check frequency
By default the frequency is set to 24 hours, i.e. repositories are checked for consistency once per day. The entry field permits an interger value from 1 (an hour) to 999 (41 days, 14 hours). - Once your settings are in place, click Save.

Save!
- Temporary removal of a repository from a node, then adding it back incorrectly.
Fix: Ensure that an rsync is performed between your restored repository and the other replicas. Don't assume that nothing has changed even if the repository has been off-line.Known Issue: Don't run a consistency check if the repository has been removed from one of the nodes.
There's currently a problem with running a consistency check on a repository if the replica on one or more or more nodes has been deleted. In this situation a "Highest Common Revision" task will appear on the dashboard and will remain permanently in a 'pending' state. Until we resolve this problem you shouldn't run the consistency checker on a repository if it has been removed from the file system of any of your nodes. -
The Consistency Check would not be expected to deal with consistency issues that pre-dated the revision at which replication was started.
Fix: Ensure consistency between replicas before you start replicating a repository. - The Consistency Check would not be expected to pick up on inconsistencies that occur very early revisions in a very large repository (revision 12 in a repository with 10,000 revisions, etc.)
Fix: These sorts of issues should be managed through Git admin best practices such as through regular, incremental backup of repositories and verifications using svnadmin. - Restoring a backup of a repository from a VM snapshot can introduce differences.
Fix: Repeat the repository restoration, account for factor's such as the use of Change Block Tracking (CBT) - Possible Git/VCS bugs that leads to non-deterministic behaviour, leading to a loss of sync.
Fix: Need to be handled on a case by case basis, subject to the nature of the problem. - Manipulation of file/folder permissions outside of Git's control will lead to divergence that will force the affected replica to become read-only.
Fix: The easiest to fix as correcting the file/ownership errors will generally result the replicas re-syncing and automatically coming out of Read-only mode. - Login to a node, click on the REPOSITORIES tab.
Go to the repository
- Click on one of the listed repositories. This will activate the below line of buttons.
Consistency Check is done on a per node basis
- Click on the Consistency check. A growl message "Invoking consistency check on repository <Repository Name>" will appear.
Consistency check in action
- Login to the Passive node, click on the Replication Group tab.
- Click on the Configure button, then change the role of the passive node so that it becomes active.
- Once the repair is completed successfully you can reverse this change in order to return to your establish replication model.
- Login to a node, click on the REPOSITORIES tab. A repository that is out-of-sync will be flagged as Local RO (Read-only) which signifies that other replica may continue to update. Note that the Status for Repo2 is marked as "Stopped" instead of "Replicating". Click on the Repair button.
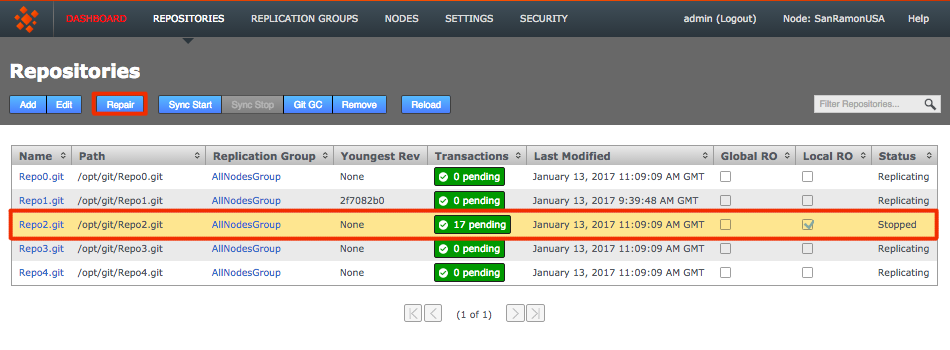
Out of sync
- The Repair Repository window will open. This runs through a three step procedure. First, select a 'helper' from the nodes that remain in replication. It may be worth while doing a test before you choose the helper to ensure that its copy of the repository is in fact the latest version. Once selected, click the Start Repair Process button. This will briefly take the selected node offline, to ensure that changes don't occur to the repository while you conduct the repair. At this point you need to login handle the repair manually.

Start the repair!
- Use the good copy of the repository on the helper node, overwriting the out-of-date/corrupted copy. We recommend using rsync for this task. There's more about using rsync in the next chapter.
Hooks will be overwritten
Take note that when restoring a repository using rsync, you will also copy across the "helper" repository's hooks, overwriting those on the destination node.
Need to maintain existing hooks?
Before doing the rsync, copy the hooks folder to somewhere safe. Then when you've completed the rsync, restore the backed-up hooks.[root@localhost repos]# rsync -rvlHtogpc /opt/repos/repo2/ root@172.16.2.41:/opt/repos/ The authenticity of host '172.16.2.41 (172.16.2.41)' can't be established. RSA key fingerprint is 9a:07:b2:bb:b6:85:fa:93:41:f0:01:d0:de:8f:e1:5d. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '172.16.2.41' (RSA) to the list of known hosts. root@172.16.2.41's password: sending incremental file list ./ README.txt format conf/ conf/authz conf/passwd conf/svnserve.conf db/ db/current db/format db/fs-type db/fsfs.conf db/min-unpacked-rev db/rep-cache.db db/txn-current db/txn-current-lock db/uuid db/write-lock db/revprops/ db/revprops/0/ db/revprops/0/0 db/revprops/0/1 db/revprops/0/2 db/revprops/0/3 db/revs/ db/revs/0/ db/revs/0/0 db/revs/0/1 db/revs/0/2 db/revs/0/3 db/transactions/ db/txn-protorevs/ hooks/ hooks/post-commit.tmpl hooks/post-lock.tmpl hooks/post-revprop-change.tmpl hooks/post-unlock.tmpl hooks/pre-commit.tmpl hooks/pre-lock.tmpl hooks/pre-revprop-change.tmpl hooks/pre-unlock.tmpl hooks/start-commit.tmpl locks/ locks/db-logs.lock locks/db.lock sent 1589074 bytes received 701 bytes 167344.74 bytes/sec total size is 1585973 speedup is 1.00 [root@localhost repos]#Once the repository is updated you should check that the fixed repository now matches the version on your helper node. - From a terminal window, delete the repository's cache file.
<repository_name>/db/rep-cache.db
This step is not essential and could result in the repository becoming slightly larger, however it removes the risk that the repaired repository will not match with the cache file. - Restart Apache. This will free up file handlers that are holding the rep-cache.db file open as well as clearing any in-memory cache data that could point to refernces that don't exist in the repaired repository.
- At this point, complete the repair process. Go back and click the "Complete Repair Process" button.
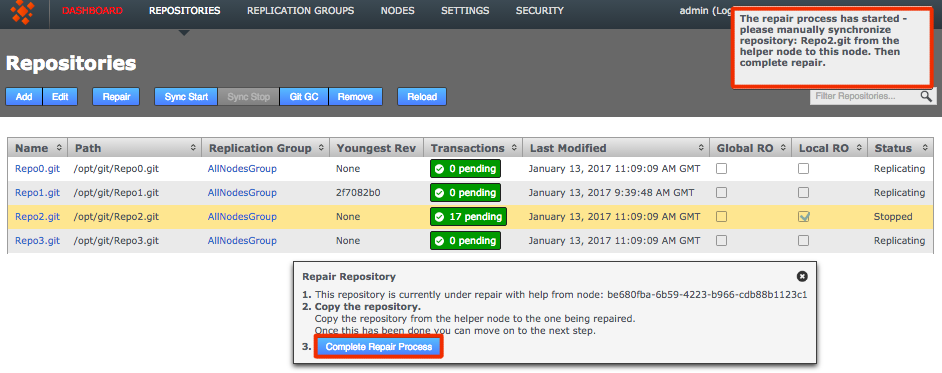
Complete!
- Looking back at the REPOSITORIES tab you'll now see that the problem repository is once again replicating.
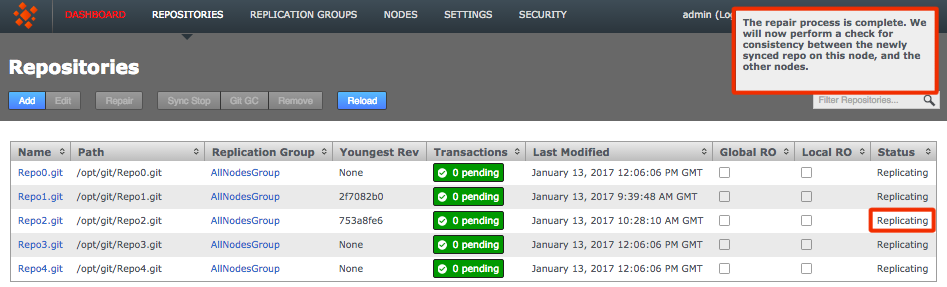
Back in sync
- Log in to the server with admin privileges. Navigate to the Git MultiSite binary directory:
/opt/wandisco/git-multisite/bin/
- Run talkback.
[root@localhost bin]# ./talkback
- You will need to provide some information during the run. Make a note of the environmental variables named below. You can then use these to modify how the talkback script runs:
[root@daily-gerrit-static-1 bin]# ./talkback ===================== INFO ======================== The talkback agent will capture relevant configuration and log files to help WANdisco diagnose the problem you may be encountering. ls: cannot access /opt/wandisco/git-multisite/replicator/gfr/bin/acp: No such fi le or directory Gathering Gerrit info.... Is the replicator currently running [Y/n]: Y Please enter replicator admin username: admin Please enter replicator admin password: retrieving details for node "8bbe11fe-8060-4553-99d0-6cff75455e58" retrieving details for node "e8e85c2c-dbb7-451a-87a3-f11fa9dc1871" Running sysInfo script to captrue maximum hardware and software information... Gathering Summary info.... Gathering Kernel info.... Gathering Hardware info.... Gathering File-Systems info.... Gathering Network info.... Gathering Services info.... Gathering Software info.... Gathering Stats info.... Gathering Misc-Files info.... THE FILE sysInfo/sysInfo_10.6.61.38-20150106-151215.tar.gz HAS BEEN CREATED BY sysInfo Please enter your WANdisco support FTP username (leave empty to skip auto-upload process): Skipping auto-FTP upload TALKBACK COMPLETE --------------------------------------------------------------- Please upload the file: /opt/wandisco/git-multisite/talkback-201501061509-daily-gerrit-static-1.qauk.wandisco.com.tar.gz to WANdisco support with a description of the issue. Note: do not email the talkback files, only upload them via ftp or attach them via the web ticket user interface. -------------------------------------------------------------- - Login to the admin console, click on the Settings tab.
- Scroll down the settings till you reach the Logging Settings block.

- Click on the Configure button.
- The Logging Settings Config page will open. Click on the drop-down menu to change the current global logger setting. This change will be applied to all loggers that have not been specified in the edited Logger settings. Loggers that you Add or Edit (specify) will always override this global setting.

- Login to the admin console, click on the Settings tab.
- Scroll down the settings till you reach the Logging Settings block.
- Click on the Configure button.
- The Logging Settings Config page will open, it has the following sections:
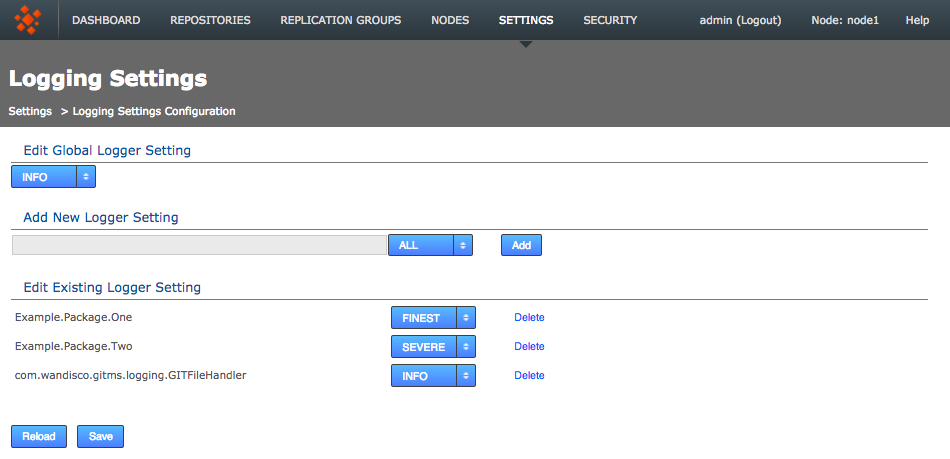
- Add New Logger Settings
- Enter the name of the logger, assign its level then click the Add button.
- Edit Existing Logger Settings
- Use the corresponding drop-down list to change the level of any of the existing loggers or click the Delete button to remove the logger. All changes thus far are immediate in effect and in-memory only. Changes are not persisted after replicator restart unless you use the save or reload button:
- Reload Logging Settings
- Click Refresh button to ditch all changes by reloading the logger settings from the <install-dir>/replicator/properties/logger.properties. file.
- Save Logging Settings
- Click Save Logging Settings to apply your changes to the above logger.properties file.
- Edit Global Logging Level
- Allows for a change to the global logging level, although not the deletion of logger settings.
- Open a terminal on your node. Navigate to the replicator directory.
$ cd /opt/wandisco/git-multisite/replicator/ - Run the following command-line utility.
$ java -jar resetSecurity.jar
- You'll be asked for new administrator credentials then prompted to restart the replicator in order for the change to be applied.
- Now login using the orginal authentication form:
- Shut down all nodes and ensure the Git MultiSite service has stopped
- On one node, open the application.properties file in a text editor. Default location:
/opt/wandisco/git-multisite/replicator/properties/application.properties
- Add the following entries to the file:
application.username=admin application.password=wandisco - Save the file, then restart the Git MultiSite service on that node.
- Copy the newly created /opt/wandisco/git-multisite/replicator/properties/users.properties file to all other nodes.
- Restart the Git MultiSite services on all nodes.
- Again, edit application.properties. This time, remove the entries added in step 3 (application.username and application.password).
- First you need to get the locationIdentity value for the node you want to change. To do this use:
curl -X get -u username:password -s http://<node IP>:8082/api/nodes | xmllint --format -
You will see something link the following example for your node:<node> <nodeIdentity>dfb1beb1-fcf0-454b-96a0-cfa90ab269d3</nodeIdentity> <locationIdentity>645acf2c-b618-11e3-b7d4-08002722bb05</locationIdentity> <isLocal>true</isLocal> <isUp>true</isUp> <isStopped>false</isStopped> <lastStatusChange>1408614664181</lastStatusChange> <attributes> <attribute> <key>eco.system.membership</key> <value>ECO-MEMBERSHIP-c0506041-b618-11e3-8957-08002783d862</value> </attribute> <attribute> <key>node.name</key> <value>svnmsplus1</value> </attribute> <attribute> <key>eco.system.dsm.identity</key> <value>ECO-DSM-64c2dfcd-b618-11e3-b7d4-08002722bb05</value> </attribute> </attributes> </node>You can see that the locationIdentity is "645acf2c-b618-11e3-b7d4-08002722bb05". - Construct a payload to send to the node, using the following XML snippet as a guide:
route1="<?xml version=\"1.0\" encoding=\"UTF-8\" standalone=\"yes\"?><routes><route><routeType>ContentDistributionType</routeType><hostname>IP-ADDRESS</hostname><port>15102</port></route></routes>" temp_file=$(mktemp ${TMP}/job.XXXXXX) echo ${route1} > ${temp_file} - Using the payload in the temp file, make a REST API call to change the Content Delivery port. The call should be made directly to the node on which you intend to change the port:
curl -s -u username:password --header "Content-Type: application/xml" -X PUT --data @"${temp_file}" http://<Node-IP>:8082/api/location/<the-node-locationIdentity>Example:
curl -s -u username:password --header "Content-Type: application/xml" -X PUT --data @"${temp_file}" http://192.168.56.200:8082/api/location/645acf2c-b618-11e3-b7d4-08002722bb05 - When the call completes successfully, the change is done without having to restart the git-multisite service. You will now see the updated value for the content dstribution port under the Settings tab of the node. Repeat this procedure for each node so that the content distribution port matches across all nodes.
Git MultiSite has two sets of logs, one set is used for application, the other logs replication activity:
1.1 Application logs
/opt/wandisco/git-multisite/
The main logs are produced by the watchdog process and contain messaging that is mostly related to getting Git MultiSite started up and running. Logs are rotated when they hit 100MB in size.
replicator -- logging the startup etc of the replicator
ui -- startup/everything to do with the UI, inc in-use logging. lightweight.
-rw-r--r-- 1 wandisco wandisco 88 Jan 15 16:53 multisite.log -rw-r--r-- 1 wandisco wandisco 220 Jan 15 16:53 replicator.20140115-165324.log -rw-r--r-- 1 wandisco wandisco 4082 Jan 15 16:53 ui.20140115-164517.log -rw-r--r-- 1 wandisco wandisco 1902 Jan 15 16:53 watchdog.log
1.2 Replicator logs
The logging for replication activity is stored within the replicator directory in the Git MultiSite installation, i.e. /opt/wandisco/git-multisite/replicator/logs. These logs take the following form:
-rw-r--r-- 1 wandisco wandisco 296785 Jan 6 14:36 gitms.log -rw-r--r-- 1 wandisco wandisco 54 Jan 6 07:34 logrotation.ser drwxr-xr-x 2 wandisco wandisco 4096 Jan 6 07:30 recovery-details drwxr-xr-x 2 wandisco wandisco 4096 Jan 6 14:34 thread-dump
The logging system has been implemented using Simple Logging Facade for Java (SLF4J) over the log4J Java-based logging library. This change from java.util.logging has brought some benefits:
This change lets us collate data into specific package-based logs, such has a security log, application log, DConE messages etc.
Logging behavior is mostly set from the log4j properties file. /git-multisite/replicator/properites/log4j.properties
# Direct log messages to a file
log4j.appender.file=com.wandisco.vcs.logging.VCSRollingFileAppender
log4j.appender.file.File=gitms.log
log4j.appender.file.MaxFileSize=100MB
log4j.appender.file.MaxBackupIndex=10
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
log4j.appender.file.append=true
# Root logger option
log4j.rootLogger=INFO, file
This configuration controls how log files are created and managed. A change to log4j configuration currently requires a replicator restart to take affect.
1.2.1 Additional log destinations (appenders)
Apache log4j provides Appender objects are primarily responsible for printing logging messages to different destinations such as consoles, files, sockets, NT event logs, etc.
Appenders always have a name so that they can be referenced from Loggers.
You can learn more about setting up appenders by reading through the Apache documenation - http://logging.apache.org/log4j/1.2/manual.html
We strongly recommend that you work with our support team before making any significant changes to your logging.
If you enable the debug mode you should consider adjusting your log file limits (increasing the maximum file size and possibly the maximum number of files).
If it is possible, consider placing the log files an a separate file system.
1.3 Logging levels
1.3.1 Changing the logging level
It's possible to change the logging levels - either temporarily to help in a current investigation, or perminently if you desire to change your ongoing logging. For making changes to logging, see 35. Logging Settings Tool.
It's still possible to modify log settings directly by editing the logger properties file:
/opt/wandisco/git-multisite/replicator/properties/logger.propertiesOnce you've made a change, you will need to restart the replicator in order for the change to take effect.
Log changes are not replicated between nodes, so each node has its own logging setup.
2. Consistency check
Consistency check is done on a per node basis. It enables you to check whether a selected repository remains in the same state across the nodes of a replication group. Follow these steps to check on consistency:
The Consistency Check tells you the last common revision shared between repository replicas. Given the dynamic nature of a replication group, there may be in-flight proposals in the system that have not yet been agreed upon at all nodes. Therefore, a consistency check cannot be completely authoritative.
Specifically, consistency checks should be made on replication groups that contain only Active (inc Active Voter) nodes. The presence of passive nodes causes consistency checks to fail.
If you run a consistency check for a repository that does not exist, the dashboard displays
[]. You also get this result if you perform an /api/consistencyCheck call on a removed node.You will receive a consistency error if you run a consistency check when there is no quorum. Consistency checks cannot verify consistency without a quorum so shouldn't be run.
If scheduled consistency checks are being skipped, possibly due to the previous check having failed, you can get the scheduled checks back into action by cancelling the previous task though the admin UI. Read how to set up Scheduled Consistency Checks.
Check the dashboard for the status of the consistency check.
Log results
It's also possible to check the results of a consistency check by viewing the replicator's log file (gitms.log). See Logs
Scheduled Consistency Checks
It's possible to have consistency checks triggered automatically on a predefined schedule. Scheduled consistency checks are run on a per-node basis using the following procedure:
Checking more often than hourly
Scheduled consistency checks are not replicated, there'd be no point as all repository replicas across all nodes are being checked anyway. You can use the fact that they are not replicated to your advantage, if you want to perform checks that are more frequent than once per hour. For example, if you have four nodes you could run an hourly check on each node, staggering the check so that one is occuring every 15 minutes. Such frequent checks wouldn't be recommended if you're deploying very large numbers of repositories.
2.1 Inconsistency: causes and cures
WANdisco's replication technology delivers active-active replication that, subject to some external factors, ensures that all replicas are consistent. However, there are some things that can happen that break consistency that would result in a halt to replication.
Loss of consistency is generally caused by external factors such as environmental differences, system quirks or user error. We've never encountered a loss of sync that resulted from a deficiency in the replication engine.
The Consistency Check will tell you the last common revision shared between repository replicas. Given the dynamic nature of a replication group it's possible that there will be in-flight proposals in the system that have not yet been agreed upon at all nodes. For this reason it isn't possible for a consistency check to be completely authoritative.
Specifically, consistency checks should be made on replication groups that contain only Active (inc Active Voter) nodes. The presence of passive nodes will cause consistency checks to fail.
2.2 Log results
It's also possible to check the results of a consistency check by viewing the replicator's log file (gitms.log). See Logs
3. Copying repositories
This section describes how to get your repository data distributed before replication.
Repositories should start out as identical at all sites. A tool such as rsync can be used to guarantee this requirement. The exception is the hooks directory which can differ as variances in site policy may require different hooks. For more information see hooks.
3.1 Copying existing repositories
It's simple enough to make a copy of a small repository and transfer it to each of your nodes. However, remember that any changes made to the original repository will invalidate your copies unless you perform a syncronzation prior to starting replication.
If a repository needs to remain available to users during the proccess, you should briefly halt access, in order to make a copy. The copy can then be transferred to each node. Then, when you are ready to begin replication, you need use rsync to update each of your replicas. Fore more information about rsync, see Synchronizing repositories using rysnc.
If an existing repository is added to a Replication Group that contains Passive nodes or a repository on a Passive node enters an Local Read-only state,
Then the UI will not offer a repair option, being unable to coordinate with the repository copy on the Passive node. The answer is to temporarily change the passive node into an active node:
4. Synchronizing repositories using rysnc
If for any reason repositories are corrupted or unable to automatically catch up it's usually possible to use rsync to get them back into sync.
From the node with the up-to-date repository, type the following commands:
rsync -rvlHtogpc /opt/git/repo/ remoteHost:/opt/SVN/
For example:
rsync -rvlHtogpc /git/Repo root@172.7.2.33:/git/
Then follow up with an additional rsync that will ensure that contents of the locks directory are identical (by deleting locks that are not present on the originating server)
rsync -rvlHtogpc --delete /path/to/repo/db/locks <Repository Name> remoteHost:/path/to/repo/db
For example:
rsync -rvlHtogpc --delete /git/Repo/db/locks root@172.7.2.33:/git/Repo/db
You can read a more detailed step-by-step guide to using rsync in the Knowledge Base article Reset and rsync repositories.
5. Recover from node disconnection
Git MultiSite can recover from a brief disconnection of a member node. It should be able to resync when the node is reconnected. The crucial requirement for MultiSite's continued operation is that agreement over transaction ordering must be able to continue. Votes must be cast and those votes must always result in an agreement. No situation must arise where the votes are evenly split between voters.
If, after a node disconnection, a replication group can no longer form agreements then replication is stopped. If the disconnected node was a voter and there aren't enough remaining voters to form an agreement, then either the disconnected node must be repaired and reconnected, or the replication group must undergo emergency reconfiguration (EMR).
5.1 EMR
If you need to permanently remove a node from one of your replication groups, i.e. an emergency reconfiguration (EMR), then you must contact WANdisco's support team for assistance. The operation poses several risks to overall operation. Therefore we recommend that you do not attempt the procedure.
EMR is a final option for recovery
The EMR process cannot be undone, and it involves major changes to your replication system. Only consider an EMR if the disconnected node cannot be repaired or reconnected in an acceptable amount of time.
After a disconnected node has been removed and a replication group reconfigured, the disconnected node should not be allowed to come back online. The DConE replication engine is unaffected by the presence of a rogue node. However, an inactive repostory may be mistaken for an active repository, although it will receive no more updates from the other replicas. You must perform a cleanup after completing an emergency reconfiguration.
Any replication group which has its membership reduced to one node will continue to exist after the emergency reconfiguration as a non-replicating group. When you have set up a replacement node you should be able to add it back to the group to restart replication.
The EMR procedure needs to be co-ordinated between sites/nodes. You must not start an EMR if an EMR procedure has already started from another node. Running multiple EMR procedures at the same time can lead to unpredictable results or cause the processes to get stuck.
6. Run Talkback
Talkback is a bash script that is provided in your Git MultiSite installation in case you need to talk to the WANdisco support team.
Manually run Talkback using the following procedure. You can run Talkback without interaction if you set up the variables noted in step 3:
If you're not using our secure FTP you can upload your talkback output files to our support website. Just attach them to your case. Read our Knowledgebase article about How to raise a support case.
7. Replication over a bad WAN link
Note: Nodes that are out of sync eventually recover.
Git MultiSite runs with a smart commit strategy and ignores all read operations so that activities like checkouts have no impact on WAN traffic. This, along with network optimization, can provide LAN-speed performance over a WAN for write operations at every location, while keeping all the repositories in sync. If a node is temporarily disconnected, or experiences extreme latency or low speeds, a node may become temporarily out of sync while transactions are queued up.
If this happens, the node will eventually catch up without administrator intervention. However, do monitor the state of your WAN connectivity to be certain that replication will be able to catch up.
If connectivity drops to almost zero for a prolonged period then this result in the node becoming isolated and increasingly out-of-sync. If this happens, you msut monitor traffic, contact WANdisco's support team and start considering contingencies. For example, consider making network changes or removing the isolated node from replication, potentially using the Emergency Reconfiguration procedure
8. Logger settings tool
Loggers are usually attached to packages. Here, the level for each package is specified. The global level is used by default, so levels specified here act as an override that takes effect in memory only - unless saved to the logger properties file.
8.1 Edit global logger settings
8.2 Add or edit logger settings
9. Disable external authentication
In the event that you need to disable LDAP or Kerberos authentication and return your deployment to the default internally managed users, use the following procedure.
10. Create a new users.properties file
In the event that you need to create a fresh users.properties file for your deployment, follow this short procedure:
11. Change content.server.port after installation
Use this procedure if you need to change the port allocated for content distribution (4321 by default), this is the replicator's payload data: repository changes etc. It's not possible to edit this value manually, you need to change it through the REST API. Here's how: