On-premises Hadoop to Amazon S3 and AWS Glue
These are an outline of the steps needed to ready your environment for migration of data and metadata.
Time to complete: 1 hour (assuming all prerequisites are met).
Recommended technical knowledge
- Linux operating system
- Apache Hadoop administration
- Hadoop Distributed Filesystem (HDFS)
- Apache Hive
- Amazon Web Services (AWS) Service configuration and management
- Amazon Simple Storage Service (Amazon S3)
- AWS Glue
Prerequisites
On-premises Hadoop cluster
All prerequisites are met for the source environment.
Network connectivity between your edge node and Amazon S3 & AWS Glue. These are some of the options available depending on your use-case:
- AWS Site-to-Site VPN - suitable for small/medium/test migrations.
- AWS Direct Connect - suitable for larger migrations (up to 100Gbps).
Ensure that all security best practices are taken into consideration when setting up either Site-to-Site or Direct Connect.
Amazon S3 and AWS Glue
For your target environment, make sure you have the following:
- An AWS account.
- An Amazon S3 bucket.
- An AWS Glue Data Catalog instance.
- Internal network configuration between AWS Glue and Amazon S3 including DNS configuration for your VPC.
- An AWS Glue connection.
- If applicable, an AWS Glue crawler configured to crawl your Amazon S3 bucket.
AWS security
All AWS services should be secured using best practices. This is a summary of those practices and which services they apply to.
Amazon S3
All Amazon S3 buckets should adhere to AWS best practices for Amazon S3. These include the following:
Use IAM to grant access to Amazon S3 buckets.
Follow IAM security best practices when creating policies.
- Create an individual IAM user/role for access to the bucket (don't use the AWS root account).
- Follow the policy of least privilege to grant read and write access to the bucket for Data Migrator. This includes limiting access through bucket policies and access control lists.
- Limit the IAM policy to the minimal rules required for Data Migrator operations on the bucket:
- List available buckets
- Obtain bucket location
- List bucket objects
- Put, delete or retrieve objects from the bucket.
IAM Access and Secret Keys are supported if your are unable to use IAM Roles.
Use
filesystem update s3awhen rotating access keys to update Data Migrator with the new key IDs.The access and secret keys can be stored or referenced in a location used by the Default AWS Credentials Provider Chain. This class can be defined when using the
--credentials-provideroption.If using the Simple AWS Credentials Provider class, the access and secret keys will be stored in the Data Migrator database.
Enable server-side encryption for your Amazon S3 bucket.
Block public access to the Amazon S3 bucket unless you explicitly require it.
AWS Glue
All AWS Glue instances should be configured using AWS security practices for Glue. These include the following:
Set up IAM permissions for Data Migrator to access AWS Glue, including:
IAM Access and Secret Keys are supported if your are unable to use IAM Roles.
Use
hive agent configure gluewhen rotating access keys to update the Data Migrator metadata service with the new key IDs.The access and secret keys can be stored or referenced in a location used by the Default AWS Credentials Provider Chain. This class is the default when not using the
--credentials-provideroption.If you enter the Static Credentials Provider Factory class, the access and secret keys will be stored in the Data Migrator metadata service database.
AWS deployment
These are some of the options to consider before creating your Amazon S3 bucket and AWS Glue instance:
AWS costs and quotas
The following table lists the required and optional AWS services that are applicable to this use-case:
| Service | Required? | Pricing | Quotas |
|---|---|---|---|
| Amazon S3 | Yes | Amazon S3 pricing | Amazon S3 quotas |
| AWS Glue | Yes | AWS Glue pricing | AWS Glue quotas |
| Site-to-Site VPN | Optional | Site-to-Site VPN pricing | Site-to-Site VPN quotas |
| Direct Connect | Optional | Direct Connect pricing | Direct Connect quotas |
| Key Management Service (KMS) | Optional | KMS pricing | KMS quotas |
See AWS pricing for more general guidance.
Install Data Migrator on your Hadoop edge node
Install Data Migrator on your Hadoop edge node.
Configuration for data migrations
Add Hadoop Distributed File System (HDFS) as source filesystem
Configure your on-premises HDFS as the source filesystem:
(CLI only) Validate that your on-premises HDFS is now set as your source filesystem:
If the filesystem shown is incorrect, delete it using
source deleteand configure the source manually:Ensure to include the
--sourceparameter when using the command above.
Add Amazon S3 bucket as target filesystem
Configure your Amazon S3 bucket as your target filesystem:
Test the S3 bucket target
Data Migrator automatically tests the connection to any target filesystem added to ensure the details are valid and a migration can be created and run.
To check that the configuration for the filesystem is correct:
UI - the target will show a healthy connection.
CLI - the
filesystem showcommand will show only a target that was successfully added:Examplefilesystem show --file-system-id myAWSBucket
To test a migration to the S3 bucket, create a migration and run it to transfer data, then check that the data has arrived in its intended destination.
Create path mappings (optional)
Create path mappings to ensure that data for managed Hive databases and tables are migrated to an appropriate folder location on your Amazon S3 bucket.
This lets you start using your source data and metadata immediately after migration, as it will be referenced correctly by your AWS Glue crawler and/or AWS Glue Studio.
Configuration for metadata migrations
Add Apache Hive as source hive agent
Configure the source hive agent to connect to the Hive metastore on the on-premises Hadoop cluster:
Test the Apache Hive source hive agent
Data Migrator automatically tests the connection to any hive agent added to ensure the details are valid and a metadata migration can be created and run.
To check that the configuration for the hive agent is correct:
UI - the agent will show a healthy connection.
CLI
Examplehive agent check --name hiveAgent
To test a metadata migration from the Apache Hive agent, create a metadata migration and run it to transfer data, then check that the data has arrived in its intended destination.
Add AWS Glue as target hive agent
Configure a hive agent to connect to AWS Glue:
Test the AWS Glue target hive agent
Data Migrator automatically tests the connection to any hive agent added to ensure the details are valid and a metadata migration can be created and run.
To check that the configuration for the hive agent is correct:
UI - the agent will show a healthy connection.
CLI
Examplehive agent check --name hiveAgent
To test a metadata migration to the AWS Glue target agent, create a metadata migration and run it to transfer data, then check that the data has arrived in its intended destination.
Troubleshooting
In the event a filesystem or hive agent could not be added, Data Migrator will give you error messages in most cases to help you discern the issue.
If no data appears to have been transferred in either a migration or a metadata migration, check Data Migrator's notifications for errors. In most cases, these will give you the information you need to diagnose any problems.
In the event of a problem you cannot diagnose, contact Support.
Network architecture
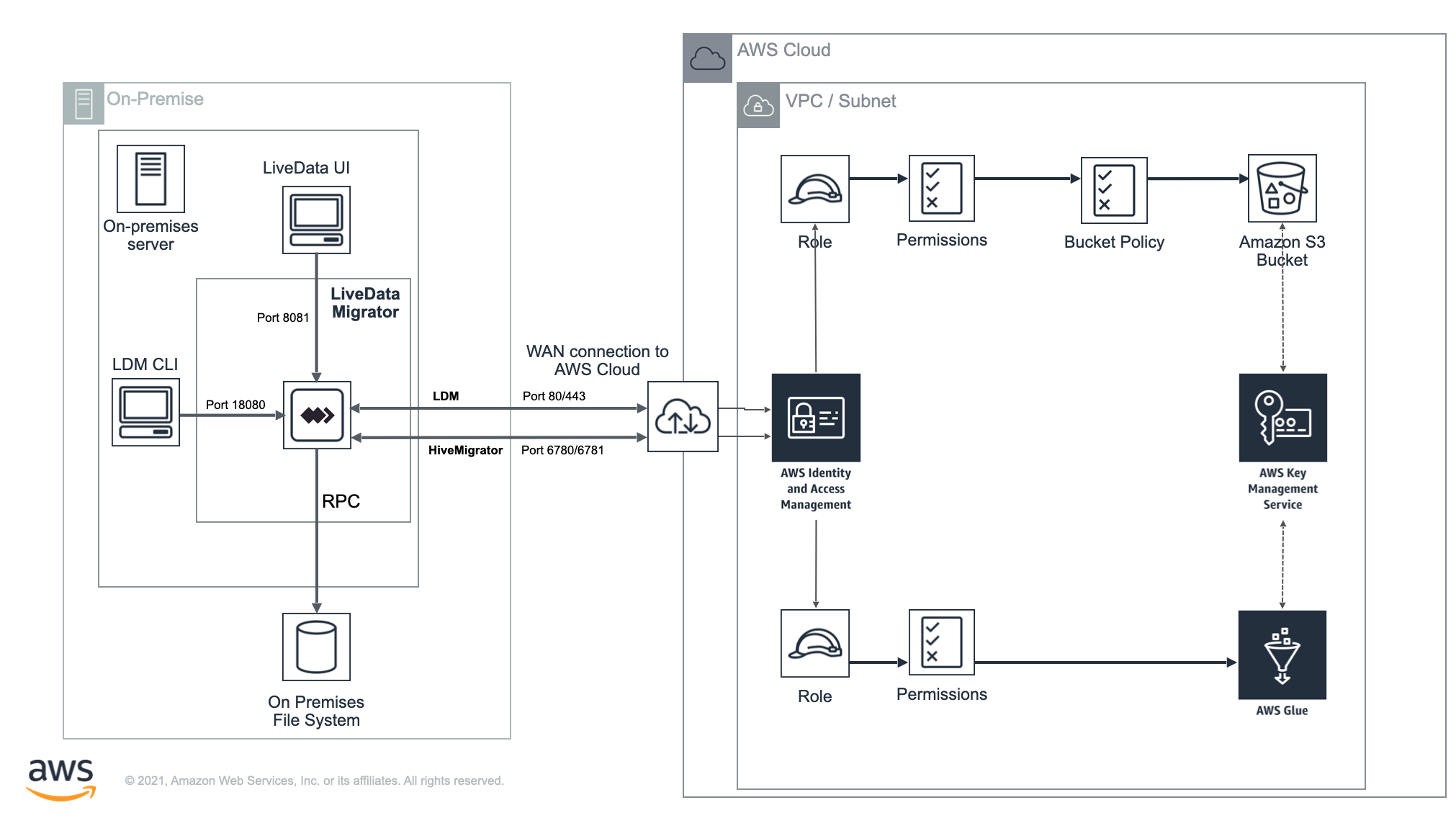
The diagram is an example of Data Migrator architecture between two environments - On-premises and AWS Cloud.
On-premises
All migration activity, both reads and writes, goes through the Data Migrator service. Data transfer to AWS is via Port 443 (HTTPS). Metadata transfer through the Hive Migrator functionality is over port 6780/6781 (HTTP/HTTPS).
Interaction with Data Migrator is handled either through the UI component (port 8081) or CLI (using the Data Migrator API port 18080). The CLI does not open any ports itself and acts as a client.
AWS Cloud
The WAN connection to AWS from the source environment (see AWS Site-to-Site VPN and AWS Direct Connect).
A VPC and Subnet (see Working with VPCs and subnets) that are configured with access to the underlying storage and metastore and necessary external connectivity to the source environment.
The IAM role and associated permissions for access to resources.
The underlying storage (Amazon S3 bucket) and metastore (AWS Glue Data Catalog).
infoBy default, S3 buckets are set as private to prevent unauthorized access. We strongly recommend that you read the following blog on the AWS support site for a good overview of this subject:
Best practices for securing sensitive data in AWS data storesThe AWS Key Management Service configured to encrypt both the Amazon S3 bucket and AWS Glue instance.
Next steps
Start defining exclusions and migrating data. You can also create metadata rules and start migrating metadata.