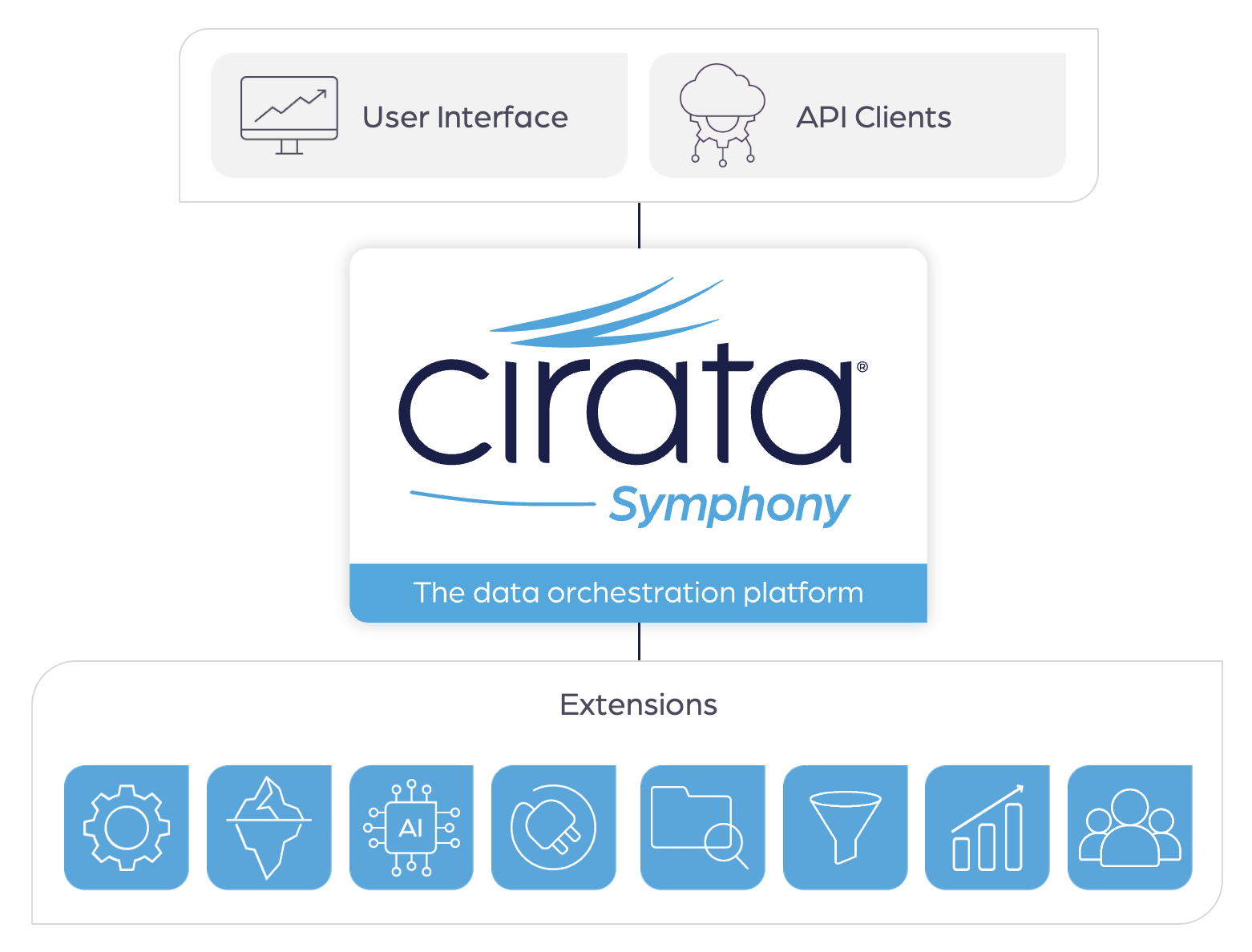
Overview
New to Symphony? See the Architecture page for an overview of how the platform is structured.
Symphony is the data orchestration platform for continuous data movement, resilience and recovery at petabyte scale, without downtime or risk. Use it to manage, replicate, transform and enable access to your data across your infrastructure, including data analytics and AI systems. These can include:
- storage services like Amazon S3, Hadoop file systems, and network file systems,
- compute platforms like Spark, Hadoop, Databricks and Snowflake,
- network transfer functionality like Cirata Data Migrator or distcp, and
- artificial intelligence technologies like large language and generative models.
Use Symphony to manage a variety of systems from one platform. It offers simple, consistent integration with your runtime environments, so that you can orchestrate all of your data systems through a single control plane.
Example Uses
Data orchestration can sound like an abstract concept. Here are some examples of how it can be used for real scenarios that you may need solutions for every day:
Data Replication
Data rarely stays in just one place...
Whether for disaster recovery, faster access from another location, or using another platform's features, replication is a core part of any data architecture.
At its simplest, data replication means choosing a source and target, and deciding when to start copying; perhaps once, on a schedule, or in response to events like source changes. It can also involve adjusting to conditions like resource limits, failures, or other factors that affect how replication performs. With large amounts of data, replication also needs to handle the changes that can occur to source data while replication is underway, and be able to verify or guarantee outcomes.
Data replication also needs to handle differences between the source and target systems, such as storage limits, naming rules, when the target can't store data in the same way as the source, or to meet business goals like cost or regulatory constraints.
Replicating data is more involved than just copying files.
Why Data Orchestration?
Even if one tool handles replication, you still need to control it based on external factors—like team needs, application requirements, or business changes. Data orchestration makes this easy, and provides the flexibility to meet future needs.
Cirata Symphony offers leading data replication capabilities.
AI Context
Language models continue to demonstrate broad applicability...
Language models like OpenAI, Anthropic, Mistral and Llama continue to demonstrate broad applicability, with increasingly capable performance against benchmarks and real-world tasks. Model vendors are also providing solutions in specific industries, like:
Anthropic Claude for Financial Services : Claude's solution for financial analysis "unifies financial data—from market feeds to internal data stored in platforms like Databricks and Snowflake—into a single interface. Access your critical data sources with direct hyperlinks to source materials for instant verification, all in one platform with expanded capacity for demanding financial workloads."
OpenAI solutions for financial services : OpenAI offers financial services solutions that automate tasks, synthesize market data, reports and research for insights, personalize client communication and that integrates with a selection of corporate data sources.
Why Data Orchestration?
AI models work better with task-specific information. Data orchestration helps deliver that context from any data platform, while ensuring security, visibility, and control.
Cirata Symphony makes context engineering simple, secure and comprehensive.
Interoperable Data
Use a common, interoperable representation for data assets...
Modern data architectures can simplify data availability and access by using a common, interoperable representation so that data assets can be:
- used from different technologies without needing to be transformed just to suit another system,
- added to and modified without requiring a central coordinator, and
- be robust from change over time, accounting for schema drift, re-partitioning and changing placement efficiently.
Technologies like Apache Iceberg are being adopted rapidly for interoperable data.
Why Data Orchestration?
Data orchestration simplifies what's needed to connect, organize, and deliver data in interoperable formats—like Apache Iceberg—so that data are available in an open format stays usable, consistent, and accessible across your architecture.
Cirata Symphony makes it easy to adopt and optimize the use of interoperable data formats.
Placement and Optimization
Minimize data costs through continuous optimization...
The costs of storing and maintaining large amounts of data can be significant. Continuous optimization can help minimize data costs by:
- eliminating overheads,
- adopting more cost effective storage choices,
- removing duplicate data assets, and
- improving adherence to business SLAs.
Why Data Orchestration?
Data orchestration can include continuous data optimization to help minimize costs and increase the efficiency of operating a large data environment.
Cirata Symphony simplifies data optimization and placement.
The applications for data orchestration aren't limited by these examples. Any requirement that spans more than one system, location, platform or technology is made more capable, flexible and robust by orchestrating the interactions between systems with an external orchestrator.
Why Symphony?
Simplicity
With Symphony, you can orchestrate operations across all your systems in a consistent way. It replaces the need to integrate separate adapters for each data system with a single, unified approach to access, security, and integration.
Without a data orchestration platform, you will need to create custom, manual connections between systems. This leads to fragile workflows that are hard to scale, maintain, and debug.
With Cirata Symphony, all of this fragile, custom effort is eliminated. Your data systems are coordinated with consistency, security and reliability, giving you full control of them directly from the platforms that you are already using.
Data First
Data is fundamental to every information system. It is the raw, unprocessed representation that can be stored and processed to produce information, or to directly drive systems that take action. It is the basic foundation for all modern technologies, and will retain its primary importance as those technologies change around it.
Your information systems benefit from putting data at the center of their architecture and operations, making the capablities of a data orchestration platform a key to enabling your use of data.
Why Data Orchestration
Data on its own, no matter how vast or high-quality, is inert. It sits in databases, data lakes, and systems across an organization, siloed and disconnected. A data orchestration platform is the connective tissue that transforms this passive resource into something an organization can actually act on. Here's why it's so fundamental:
It solves the coordination problem
Modern organizations don't have one data source—they have dozens or hundreds: CRMs, ERP systems, cloud storage, streaming pipelines, third-party APIs, IoT sensors, and more. Each produces data in different formats, on different schedules, at different volumes. Without interoperable data representations and data orchestration, moving and aligning this data requires manual intervention or brittle, one-off scripts. A data orchestration platform automates the sequencing, scheduling, and dependency management of data workflows, ensuring the right data gets to the right place at the right time, reliably.
It turns pipelines into a coherent system
Individual data pipelines—Extract, Transform, Load (ETL) processes, for example—are useful but limited in isolation. Orchestration elevates them into an interconnected system where workflows are aware of each other. If a pipeline feeding a downstream analytics process fails, the orchestration platform catches it, handles errors, retries tasks, and prevents bad or incomplete data from propagating. This reliability is what makes downstream decisions trustworthy.
It operationalizes data at scale
A business analyst can manually pull and clean a dataset once. But doing that thousands of times, across teams, consistently and without error, requires automation. Orchestration platforms handle scale by managing compute resources, parallelizing tasks, and scheduling jobs without human bottlenecks. This is what allows data to be leveraged continuously rather than in one-off bursts.
It enforces governance and observability
Knowing where data came from, how it was transformed, and what touched it along the way—data lineage—is critical for compliance, debugging, and trust. Orchestration platforms provide visibility into every step of a workflow, making it possible to audit pipelines, trace errors back to their source, and demonstrate regulatory compliance. Without this, data can't be trusted, and data that can't be trusted can't be leveraged.
It bridges data producers and consumers
Data engineers, scientists, analysts, and business users all interact with data differently and on different timescales. An orchestration platform acts as the mediator, ensuring that data produced by one team is reliably, consistently, and promptly available to those who need to consume it. It decouples production from consumption, so teams aren't blocked waiting on each other.
It enables the full data value chain
Ultimately, the reason organizations collect data is to derive value from it through analytics, machine learning, operational decisions, or customer experiences. None of that is possible without reliable data delivery. Orchestration is the infrastructure layer that makes every other data capability possible. Machine learning models need clean, timely training data. Dashboards need fresh, accurate feeds. Automated decisions need real-time inputs. Strip away orchestration and all of those use cases collapse.
In essence, a data orchestration platform doesn't just move data around; it imposes order, reliability, and intentionality on what would otherwise be chaos. It's the difference between an organization that has data and one that can genuinely use it.
Extensibility
Symphony is flexible and easy to extend. You can add new features at any time using extensions, which connect to external systems like storage, compute platforms, language models, or data transfer tools.
Cirata provides a collection of production-ready extensions for important data requirements, including:
- Data Migrator for scalable, live data transfer,
- Ice Flow for monitoring and replicating data assets in the interoperable Apache Iceberg table format,
- Cirata Intelligence for integrating Symphony with language models to apply artificial intelligence techniques easily to your data systems,
- Cirata Observability for OpenTelemetry metrics generation and collection, and
- Cirata Orchestration for workflow orchestration with Prefect and Airflow.
You can also implement your own extensions to integrate with systems that may be unique to your environment. Cirata provides libraries for doing this easily using Java, Go and Python.
Interoperability
Cirata Symphony gives you full access to your data systems through REST APIs from a single endpoint, secure high-speed messaging, the Symphony user interface, and client libraries for use in notebooks or custom code.
Functionality added by extensions is made available immediately and automatically to all of the interfaces, APIs, and libraries provided by Symphony. No additional step is required after running an extension before you can begin using it.
Security
Every Symphony user controls who can access the systems it enables. Access is granted through tokens linked to API keys, each with customizable, fine-grained capabilities. Both clients and extensions need a token to connect to Symphony, and users can update the capabilities of an API Key at any time.
For organizations that need centralized permission management, Symphony supports Role-Based Access Control (RBAC). RBAC maps identity provider groups to Symphony roles, each defining a ceiling on the capabilities that members can request. This integrates with enterprise directories like LDAP and Active Directory to enforce consistent access policies across teams.
Symphony employs a zero trust security model. Instead of assuming anything inside a security perimeter is safe, zero-trust requires continuous verification of every user, extension, and operation, regardless of location. Zero-trust security protects against internal threats and compromised systems. Even if attackers get past other defenses, their access is limited. This approach is essential for modern data setups across cloud, remote, and multi-platform environments.
Next Steps
Ready to deploy Symphony? See the Installation Guide for instructions on setting up a new instance using Docker Compose, Linux, or Kubernetes.